September 2013 | Estimated reading time: 10 minutes
Overview
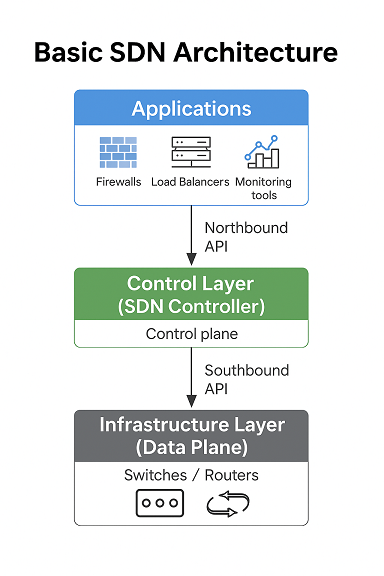
Software-Defined Networking (SDN) has reshaped the way we think about
network architecture. After exploring the concepts and architectures in
Part 1 and diving into practical deployment models in Part 2, we now
explore the real-world challenges SDN faces in 2013 and what the road
ahead might look like.
Challenge #1: Industry Maturity
While OpenFlow and SDN have garnered significant attention, the
industry is still in a state of flux. There is no single unified SDN
standard, and interoperability between vendors remains a major barrier.
Traditional hardware vendors are adapting slowly, while startups and
open initiatives push forward aggressively.
For SDN to gain mainstream traction, clearer standards must emerge.
The Open Networking Foundation (ONF) is taking steps, but competing
agendas slow progress. In production environments, CIOs and network
architects are wary of deploying technology that lacks maturity and
long-term vendor support.
Challenge #2: Performance and Scalability
Centralized controllers are core to SDN, but they also pose potential
performance bottlenecks. Latency introduced by
control-plane-to-data-plane communications must be minimized.
Scalability across hundreds or thousands of devices requires
hierarchical control models, and while proposed, these are not yet
proven in the field.
Additionally, data centers using high-throughput architectures with
10GbE or 40GbE interfaces raise concerns about the controller’s ability
to respond in time-sensitive operations. Researchers are exploring
distributed controller clusters to address this, but adoption is slow.
Challenge #3: Reliability and High Availability
Networks must be resilient. Placing intelligence in a centralized
controller raises questions: What happens if the controller fails? How
do we maintain state, ensure consistency, and resume operations quickly?
Current SDN controller platforms like Floodlight and NOX are
improving support for clustering and failover, but these features are
still experimental in many deployments. HA (High Availability)
mechanisms, traditionally native to network hardware, now must be
reengineered in software.
Challenge #4: Security Implications
SDN opens both opportunities and vulnerabilities. While it offers
centralized policy enforcement, a compromised controller can be
catastrophic. Attackers who gain access to the SDN control layer could
redirect traffic, disable services, or inject malicious flows across the
network.
Furthermore, APIs used to interface with the controller (e.g.,
RESTful APIs in OpenDaylight) must be secured with strong authentication
and access control mechanisms. In 2013, controller security is still an
underdeveloped area, requiring greater industry focus.
Challenge #5: Organizational Resistance
Change in IT is not just technical—it’s cultural. Many networking
teams are deeply familiar with CLI-driven device configurations,
vendor-specific features, and decades of best practices. Moving to SDN
requires rethinking network design, tools, and roles.
For example, network engineers must now collaborate with developers
and DevOps teams to write automation scripts and manage network APIs.
This cultural shift—toward programmability and abstraction—is slow and
met with skepticism in many traditional enterprises.
Challenge #6: Integration with Legacy Infrastructure
Few organizations are in a position to replace their entire network
stack. SDN must coexist with legacy systems, often requiring overlay
networks (like VXLAN or NVGRE) or hybrid deployments.
This raises questions around flow visibility, troubleshooting, and
management. Bridging physical and virtual environments introduces
complexity, especially in mixed-vendor environments where APIs and
control mechanisms differ widely.
Forecasting the Future: 2014–2020
Despite these challenges, SDN’s trajectory remains promising. Here’s what we expect to see in the coming years:
- Controller evolution: Maturity and consolidation around a few robust, open-source controller platforms (e.g., OpenDaylight).
- OpenFlow 1.4+ adoption with broader hardware support and new feature sets.
- Integration with orchestration tools like OpenStack, Puppet, and Chef for full-stack automation.
- Northbound API standardization to enable application portability and development.
- Wider SDN trials in universities, financial firms, and telecom providers.
As with all foundational shifts, progress will be incremental. SDN in
2013 is comparable to server virtualization in 2003: full of potential,
but not yet ready for mission-critical, widespread production in most
enterprises.
Looking Beyond SDN: Toward NFV and Intent-Based Networking
Already in 2013, we see the emergence of **Network Functions
Virtualization (NFV)**—the idea of abstracting network services (like
firewalls, load balancers, WAN optimizers) from dedicated appliances and
running them on general-purpose x86 servers.
Similarly, **intent-based networking** is being discussed in academic
circles. This would allow administrators to describe what the network
should do, and let the SDN system implement the logic automatically—a
powerful idea, but still largely conceptual at this stage.
Conclusion
SDN is not a passing trend. The challenges are real, but so are the
benefits. Like any transformative technology, it requires time,
refinement, and ecosystem buy-in. As we close this deep dive series,
it’s clear that SDN is poised to influence the next decade of
networking.
The architects and engineers who embrace this change—not just in
tools, but in mindset—will shape the networks of tomorrow. Those who
resist risk being left behind in an increasingly programmable world.
This concludes our 3-part SDN Deep Dive Series. Thank you for
joining us on this exploration of one of the most impactful evolutions
in networking since the advent of Ethernet.
Eduardo Wnorowski is a network infrastructure consultant and SDN researcher.
With over 18 years of experience in IT and consulting, he helps
organizations understand emerging technologies like SDN with clarity and
technical depth.
LinkedIn Profile